
Time to share some tinkering, in the hopes that somebody, somewhere, might find it helpful. 🙂
Regular readers will know that I’m interested in how historians can approach web archives, as discussed in a three part series in late 2012 (see part one, two, and three). As I’ve stressed, in both tweets and in some draft writing: Historians need to understand web archives, however, as we will be professional end users of these archives. We played a critical role in shaping the modern practice of traditional archiving. Let us make sure that historians are present for the next step. There’s a conversation, but its largely amongst people involved in web archiving as creators rather than as users.
[if you want to skip to my code, it’s here]
So here’s me positing a problem: Some web archives do not have description, so you aren’t sure what you’re going to find inside. This includes some just-in-time web saves, like this mirror of the Montreal Mirror’s website. There’s always an item listing, automatically generated, that lets you know what exactly is in the website. When dealing with wide web crawl data, part of that massive 80TB dataset, this is a life saver. Very briefly: Web ARChive files are complicated containers of multiple files – ActiveHistory.ca, for example, is made up of over 18,000 files. That’d choke a file system, but you can turn it into one Web ARChive that you can play with later.
Furthermore, these WARC files are too big. Wouldn’t it be nice if you could, at a glance, see what ianmilligan.ca is about without having to read what I’m writing here? (yes, but also imagine if you were just looking at a bunch of visualizations – would be invaluable in a research project)
But for the historian, it’s not terribly useful in and of itself. What if we had a lot of these files, how could we quickly see what related to our topic, and what didn’t? Would we be able to automate it?
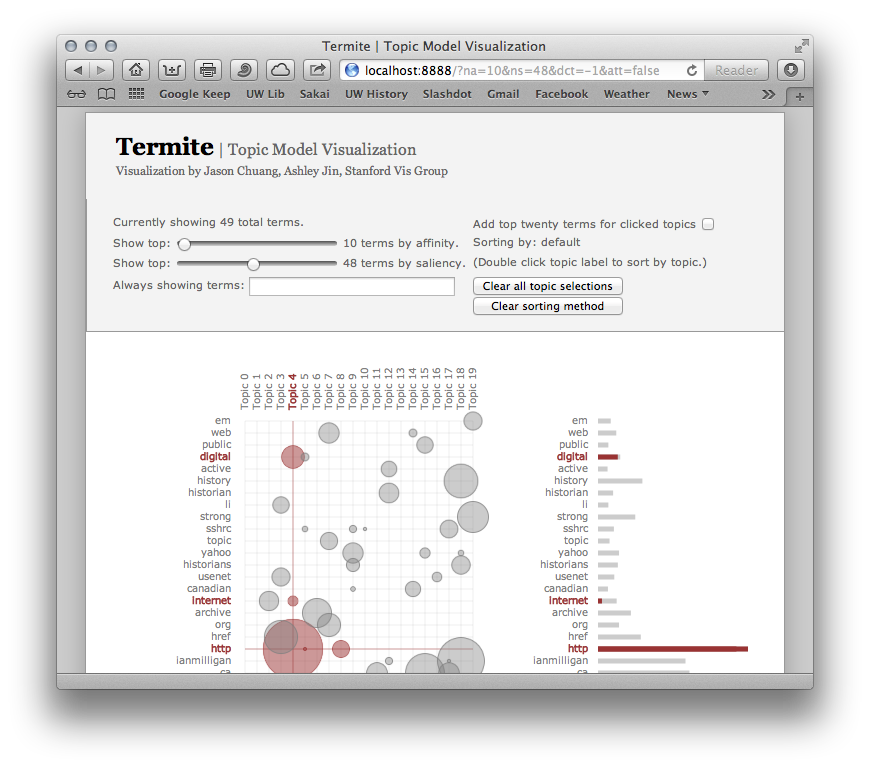
Here’s my idea, which I cooked up as a way to learn some more technical skills and invent a tool to help me in my workflow. What if we could take a Web ARChive file (WARC) and then hook it up to a topic modelling visualizer, like Stanford’s Termite [see their paper here]? This flow would ideally take a WARC file and then give us an output like this:

Termite is great, but requires its data formatted in a particular way: a file number and then a document on one single line, in tab-separated format. It isn’t terribly friendly to just dump websites into. This is preliminary work, started two days ago, simultaneous with me learning how to script in bash. It works for me, but there’s no sense in me working in a bubble.
Here is my attempt to introduce a workflow, written in Bash, drawing on various Python tools, written on MAC OS X and presumably compatible with Linux. What it does is the following:
(1) Finds a website, such as http://ianmilligan.ca, and mirrors it all into a single WARC file
(2) Transforms that WARC file into a full-text searchable index, which is far more usable in terms of size. Downsides: we lose some of the context provided by images, etc. If images have alt-image tags, those are filtered in with the text.
(3) Takes that full-text searchable index and transforms into Termite format, each individual file that makes up a WARC being given a single line.
How does it work?
Step One: Install Initial Tools
WGET: It requires wget, with WARC functionality (so no old versions). If you don’t have that, you’ll need to install it. If you’re on a MAC, you need to download xCode, command line tools, and compile it. Follow the specific instructions in my Programming Historian piece.
LYNX: These tools use Lynx to read the WARCed webpages and display them. Newer versions use Beautiful Soup 4, but I’m sticking with Lynx for now (I’ve been working with it for a while and am fairly impressed). Follow the detailed instructions here.
Step Two: Download and Install Stanford/Termite
Remarkably for such a project, the documentation is exceptional. They’re on github, so check it out there.
Step Three: Download and Install Historian-WARC-1 Files
For these, check out my github repository here.
Download them all to a directory (click the zip button above for convenience). The easiest way is to place all these files into the same directory that you have Stanford-Termite running.
You’ll need to initialize the WARC-Tools. In your terminal window, in the /WARC/Hanzo-Warc directory, run the following commands:
./setup.py build
sudo ./setup.py build install
You’ll be asked for your root password on the latter.
Step Four: Point all the Directories at the Right Place
For the Historian-WARC-1 files, you’ll need to change a few things.
Editing All-Together.sh, make sure to:
Change the URLTOGET value to the website you’re interested in looking at. You might want to change the OUTPUT field too.
Then you’ll need to change, in line 38, the path to the warc-tools-mandel directory.
Then, editing TRIAL.CFG, make sure to:
Change the path to the directory you’ve installed everything in. There are three of these. You may also need to alter the number_of_seriated terms variable as well.
Otherwise, try to read the comments, and feel free to leave comments below. If it all works, you can run this script – it grabs a website, WARCs it, and then visualizes it in termite on localhost:8888.

Hello, nice article. Could you please share a sample of formatted file which need to be fed into Termite as I am facing difficulty in formating my corpus in the format Termite wants.
Please share the file to ankitksharma11588@gmail.com
Hi Ankit,
In bash the following commands format a corpus into termite-compatible format. I am on the road right now but when I am in the office I will e-mail you example data.
sed 's .\{4\} ' fulltext.txt > fulltext2.txt
cat -n fulltext2.txt | perl -pe "s/^\s*(\d+)\s+/\1\t/" > fulltext3.txt
sed -i.old $'s/\xE2\x80\xA8/ /g' fulltext3.txt # removes weird unicode (hex 2028) line break
sed -n 1,xp fulltext3.txt > lines.txt #where x is the number of lines you want to create
Ian